
Due to the need to satisfy the balance condition, the n different systems must be synchronized whenever a swap is attempted. This synchronization is in Monte Carlo steps, rather than in real, wall clock time. If we define the simulation events between each attempted swap as a Monte Carlo step, then at the beginning of each Monte Carlo step, each replica must have completed the same number of Monte Carlo steps and be available to swap configurations with other replicas. This constraint introduces a potentially large inefficiency in the simulation, as different replicas are likely to require different amounts of computational processing time in order to complete a Monte Carlo step. This inefficiency is not a problem on a single processor system, as a single processor will simply step through all the replicas to complete the Monte Carlo steps of each. This inefficiency is a significant problem on multi-processor machines, however, where individual CPUs can spend large quantities of time idling as they wait for other CPUs to complete the Monte Carlo steps of other replicas.
Traditionally, each processor on multi-processors machines has been assigned one replica in parallel tempering simulations. It is our experience that this type of assignment is generally highly inefficient, with typical CPU idle times of 40 to 60%. When one takes into account that the lower-temperature systems should have more moves per Monte Carlo step due to the increased correlation times, the idle time rises to intolerable levels that can approach 95%.
The algorithm can allocate the replicas to the processors in two different ways so that the simulation is conducted either with minimum CPU idle time (theoretically 100% efficiency) or at minimum real wall clock time but with a small loss of efficiency (typically 3 to 8%).
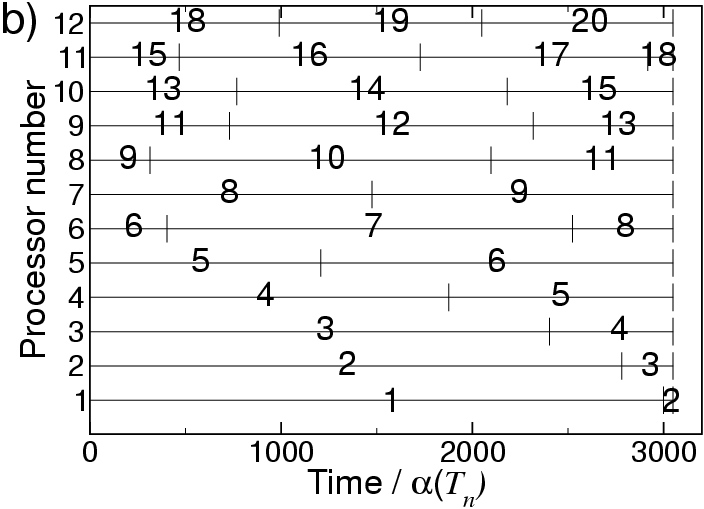
An example of how the algorithm allocates replicas to processors is shown in the figures below. Figure a) shows the usual one-replica-per-processor allocation and Figure b) shows how the algorithm allocates the same jobs to only 12 processors but with only a small increase in real wall clock time (100% efficiency option).
scheduler. To make use of
the subroutine
scheduler.h in the program that will call
scheduler
scheduler subroutine from your code
Also included in the download is an example program called
call_test.c that calls
scheduler and writes the output from the
subroutine to the screen, and a makefile to make the executable
for this example program.
We ask that you cite our paper [1] in any publications that result from
the use of the scheduler subroutine.
scheduler you need to pass as arguments the number of replicas,
nsim, the option type, option, which should be set
to 0 for maximum efficiency or 1 for minimum wall clock time, and α(Ti)
and Nmove(Ti)
for each of the replicas. The scheduler algorithm is declared as follows:
void scheduler(int nsim, int option, double *alpha,
double *Nsteps, int *nproc, int *njobs,
double job[nprocMAX][nsimMAX][2]);
where nprocMAX and nsimMAX are respectively
the maximum number of homogeneous processors and replicas allowed
in the code (set at 50 for both but can easily be altered in
scheduler.h), α[nsimMAX] is a one dimensional
array that contains the value of α(Ti)
for each of the replicas,
Nmove[nsimMAX] is a one dimensional
array that contains the value of
Nmove(Ti)
for each of the replicas, nproc is the number of processors
required to perform the simulation, njobs[nprocMAX] is a one
dimensional array that contains the number of different replicas that will
be simulated on each processor, and job is a three
dimensional array that contains the main output from the algorithm.
job[i][j][0] gives the replica number of the jth + 1
job on processor i + 1, job[i][j][1] gives the
length of time the processor spends on the replica, and
job[i][j][2] gives the number of MC moves that the processor
is responsible for on the replica. The maximum value of j to
be accessed for each processor, i, is given by
njobs[i]-1.
scheduler.c is unsupported software.